关于 Flink checkpoint,都在这里(一)
cocoFlink checkpoint 一直以来都是 Flink 引以为豪的机制之一,它为 Flink 状态流处理保驾护航。但是一直以来笔者都对于 checkpoint 的理解仅限于 Flink 官网和一些博客中的介绍,在实践层面一直是开箱即用的阶段,没有进行过深入的了解和研究。但是作为 Flink 的重要机制之一,无论从一个 Flink 粉的角度,还是从问题定位与优化的角度,都应该对它有更深入、更全面的了解。本篇文章中以问题驱动的方式进行讨论。同时也欢迎在评论区留言,评论区的一些问题会收录到本系列的博客中。
# 1:什么是 checkpoint?
我们常常这样描述:“Flink 在执行 checkpoint 过程中…”。通过语境我们可以了解到 checkpoint 是 Flink Job 的一个动作(或者说 Flink 的一种机制)用来把各个算子的状态(state)存储到状态后端(state-backend)中。Flink 会周期性的执行 checkpoint 以保证状态后端中的状态保持最新。
当 Flink job 出现异常时(如,网络问题导致其中一个 TaskManager 失联),Flink 基于 checkpoint 生成的状态快照进行状态恢复,从而保证数据结果的一致性。我们称这个过程为容错(fault tolerance,即 job 出现异常后能够自动恢复)。
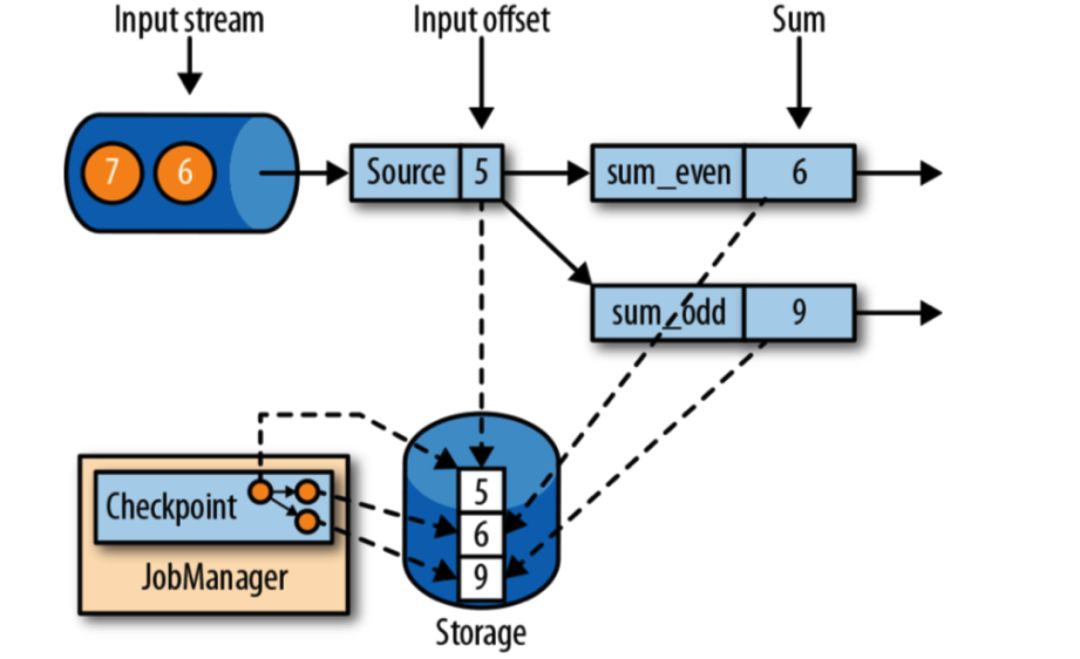
举个例子,假设我们 1)有一个 Kafka topic 有事件序列 e = [1, 2, 3, 4, 5, 6, 7],Flink source 消费该 topic,然后发送给下游的 keyBy 算子。2)keyBy 算子通过 e % 2 生成 key 并发送到下游。3)下游 reduce 算子计算 sum,并将结果发送给 sink ,4)然后在控制台输出。
这个示例中 source、reduce 都包含了状态:source 中包含了 ListState 来存储当前消费 Kafka topic 的 offset,reduce 算子中包含了 ValueState 存储当前 sum 的计算结果。我们当然可以通过 List<Long> 来保存 Kafka topic offset,通过 long 保存 sum 的计算结果。那么 Flink 就无法感知到算子中是否有状态需要持久化到状态后端,异常时也无法进行状态的恢复。
我们假设 offset=5 时任务出现了异常,reduce 中的状态将会丢失。job 恢复后将从 e = 6 开始消费,reduce 的 sum 结果将会因之前的状态丢失导致出现错误的结果。但是如果使用了状态与 checkpoint 机制,则可以恢复之前的计算结果,从而保证恢复后的结果数据的准确性。
总的来说,checkpoint 是 Flink 容错机制,基于 Flink State 一起可以帮助用户在 job 异常时进行状态恢复。那么其他的分布式计算框架(如,Spark)是如何进行容错的呢?下一篇对了比 Spark Stream、Storm、Flink 容错机制。
以上示例可以从 github 中下载代码进行测试。